1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.DataOutputStream; 4 import java.io.FileOutputStream; 5 import java.io.IOException; 6 import java.io.ObjectOutputStream; 7 import java.io.Serializable; 8 9 import org.apache.hadoop.io.Writable;10 11 public class Test2 {12 public static void main(String[] args) throws IOException {13 Student stu = new Student(1, "张三");14 FileOutputStream fileOutputStream = new FileOutputStream("d:/111");15 ObjectOutputStream objectOutputStream = new ObjectOutputStream(fileOutputStream);16 objectOutputStream.writeObject(stu);17 objectOutputStream.close();18 fileOutputStream.close();19 //我们一般只关注stu对象的id和name两个属性总共12个字节.但是Java的序列化到硬盘上的文件有175个字节.20 //Java序列化了很多没有必要的信息.如果要序列化的数据有很多,那么序列化到磁盘上的数据会更多,非常的浪费.21 //Hadoop没有使用Java的序列化机制.如果采用会造成集群的网络传输的时间和流量都集聚的增长.22 //Hadoop中自己定义了一个序列化的接口Writable.23 //Java序列化中之所以信息多是因为把 类之间的的继承多态信息都包含了.24 25 StuWritable stu2 = new StuWritable(1, "张三");26 FileOutputStream fileOutputStream2 = new FileOutputStream("d:/222");27 DataOutputStream dataOutputStream2 = new DataOutputStream(fileOutputStream2);28 stu2.write(dataOutputStream2);29 fileOutputStream2.close();30 dataOutputStream2.close();31 }32 }33 34 class Student implements Serializable{35 private Integer id;36 private String name;37 38 public Student() {39 super();40 }41 public Student(Integer id, String name) {42 super();43 this.id = id;44 this.name = name;45 }46 public Integer getId() {47 return id;48 }49 public void setId(Integer id) {50 this.id = id;51 }52 public String getName() {53 return name;54 }55 public void setNameString(String name) {56 this.name = name;57 }58 59 }60 61 62 class StuWritable implements Writable{63 private Integer id;64 private String name;65 66 public StuWritable() {67 super();68 }69 public StuWritable(Integer id, String name) {70 super();71 this.id = id;72 this.name = name;73 }74 public Integer getId() {75 return id;76 }77 public void setId(Integer id) {78 this.id = id;79 }80 public String getName() {81 return name;82 }83 public void setNameString(String name) {84 this.name = name;85 }86 87 public void write(DataOutput out) throws IOException {88 out.writeInt(id);89 out.writeUTF(name); 90 }91 92 public void readFields(DataInput in) throws IOException {93 this.id = in.readInt();94 this.name = in.readUTF();95 }96 97 } 使用Java序列化接口对应的磁盘上的文件: 共175个字节

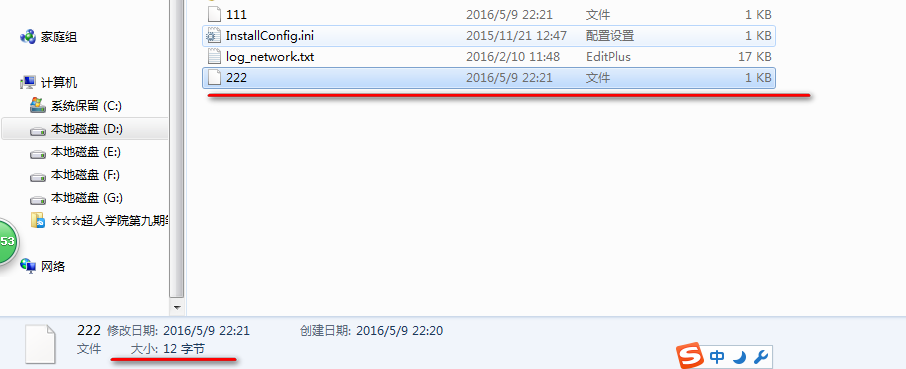
使用Hadoop序列化机制对应的磁盘文件: 共12字节
如果类中有继承关系:
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.DataOutputStream; 4 import java.io.FileOutputStream; 5 import java.io.IOException; 6 import java.io.ObjectOutputStream; 7 import java.io.Serializable; 8 9 import org.apache.hadoop.io.Writable;10 11 public class Test2 {12 public static void main(String[] args) throws IOException {13 //我们一般只关注stu对象的id和name两个属性总共12个字节.但是Java的序列化到硬盘上的文件有175个字节.14 //Java序列化了很多没有必要的信息.如果要序列化的数据有很多,那么序列化到磁盘上的数据会更多,非常的浪费.15 //Hadoop没有使用Java的序列化机制.如果采用会造成集群的网络传输的时间和流量都集聚的增长.16 //Hadoop中自己定义了一个序列化的接口Writable.17 //Java序列化中之所以信息多是因为把 类之间的的继承多态信息都包含了.再重新构建的时候可以保持原有的关系.18 19 StuWritable stu2 = new StuWritable(1, "张三");20 stu2.setSex(true);21 FileOutputStream fileOutputStream2 = new FileOutputStream("d:/222");22 DataOutputStream dataOutputStream2 = new DataOutputStream(fileOutputStream2);23 stu2.write(dataOutputStream2);24 fileOutputStream2.close();25 dataOutputStream2.close();26 }27 }28 29 30 31 class StuWritable extends Person implements Writable{32 private Integer id;33 private String name;34 35 public StuWritable() {36 super();37 }38 public StuWritable(Integer id, String name) {39 super();40 this.id = id;41 this.name = name;42 }43 public Integer getId() {44 return id;45 }46 public void setId(Integer id) {47 this.id = id;48 }49 public String getName() {50 return name;51 }52 public void setNameString(String name) {53 this.name = name;54 }55 56 public void write(DataOutput out) throws IOException {57 out.writeInt(id);58 out.writeBoolean(super.isSex());59 out.writeUTF(name); 60 }61 62 public void readFields(DataInput in) throws IOException {63 this.id = in.readInt();64 super.setSex(in.readBoolean());65 this.name = in.readUTF();66 }67 68 }69 70 class Person{71 private boolean sex;72 73 public boolean isSex() {74 return sex;75 }76 77 public void setSex(boolean sex) {78 this.sex = sex;79 }80 81 }
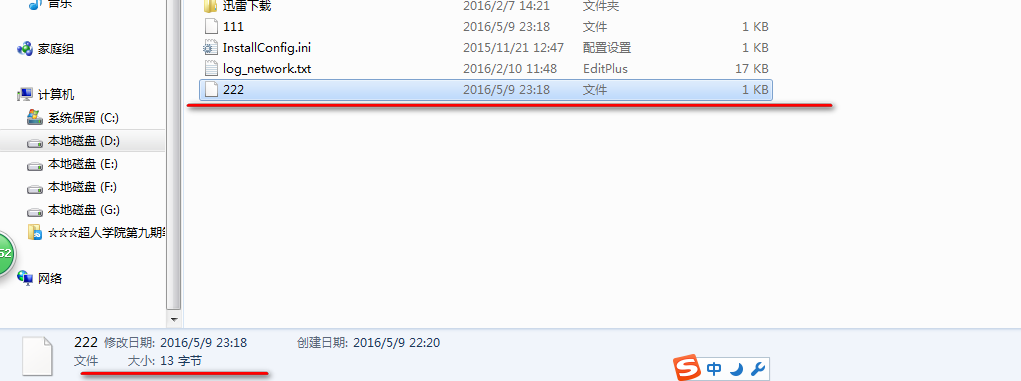
这样序列化到磁盘上的文件: 13个字节 多了一个boolean属性,相比上面多了一个字节.
如果实例化对象中含有类对象.
1 import java.io.DataInput; 2 import java.io.DataOutput; 3 import java.io.DataOutputStream; 4 import java.io.FileOutputStream; 5 import java.io.IOException; 6 import java.io.ObjectOutputStream; 7 import java.io.Serializable; 8 9 import org.apache.hadoop.io.Writable;10 11 public class Test2 {12 public static void main(String[] args) throws IOException {13 //我们一般只关注stu对象的id和name两个属性总共12个字节.但是Java的序列化到硬盘上的文件有175个字节.14 //Java序列化了很多没有必要的信息.如果要序列化的数据有很多,那么序列化到磁盘上的数据会更多,非常的浪费.15 //Hadoop没有使用Java的序列化机制.如果采用会造成集群的网络传输的时间和流量都集聚的增长.16 //Hadoop中自己定义了一个序列化的接口Writable.17 //Java序列化中之所以信息多是因为把 类之间的的继承多态信息都包含了.再重新构建的时候可以保持原有的关系.18 19 StuWritable stu2 = new StuWritable(1, "张三");20 stu2.setSex(true);21 FileOutputStream fileOutputStream2 = new FileOutputStream("d:/222");22 DataOutputStream dataOutputStream2 = new DataOutputStream(fileOutputStream2);23 stu2.write(dataOutputStream2);24 fileOutputStream2.close();25 dataOutputStream2.close();26 }27 }28 29 class StuWritable extends Person implements Writable{30 private Integer id;31 private String name;32 private Student student;33 34 public StuWritable() {35 super();36 }37 public StuWritable(Integer id, String name) {38 super();39 this.id = id;40 this.name = name;41 }42 public Integer getId() {43 return id;44 }45 public void setId(Integer id) {46 this.id = id;47 }48 public String getName() {49 return name;50 }51 public void setNameString(String name) {52 this.name = name;53 }54 55 public void write(DataOutput out) throws IOException {56 out.writeInt(id);57 out.writeBoolean(super.isSex());58 out.writeUTF(name); 59 out.writeInt(student.getId());60 out.writeUTF(student.getName());61 }62 63 public void readFields(DataInput in) throws IOException {64 this.id = in.readInt();65 super.setSex(in.readBoolean());66 this.name = in.readUTF();67 this.student = new Student(in.readInt(),in.readUTF());68 }69 70 }71 72 class Person{73 private boolean sex;74 75 public boolean isSex() {76 return sex;77 }78 79 public void setSex(boolean sex) {80 this.sex = sex;81 }82 83 }
如果我们Student中有个字段是Writable类型的.
怎么样序列化?